From Megahertz to Teraflops#
How kept computational power growing?#
With Dennard scaling hitting practical boundaries (the “Power Wall”) around 2005, leading to the stagnation of CPU clock speeds at roughly 4 GHz it was by no means that we witnessed a stagnation in usable computing power. In fact, the number of calculations computers were able to perform, kept on increasing almost as if the CPU clock speed had no influence on performance.
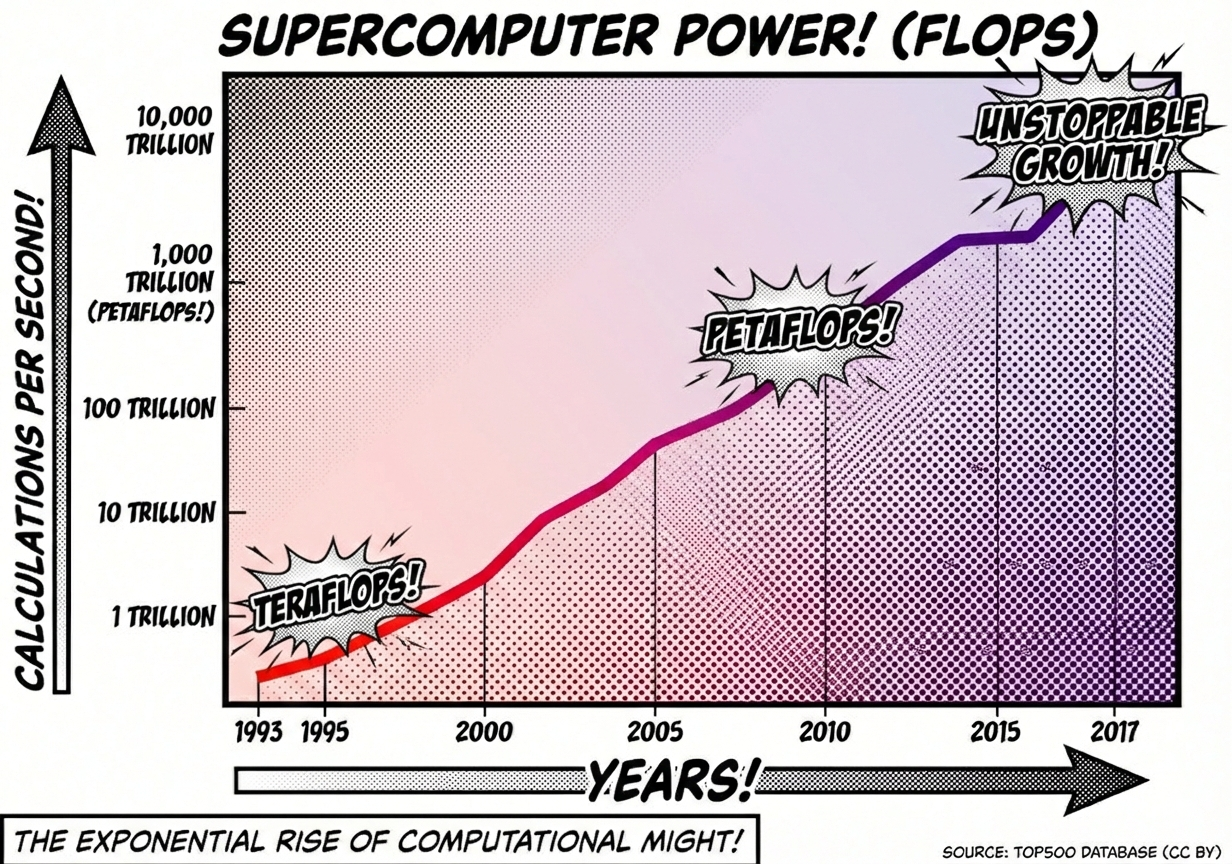
This continued performance increase was the result of drastic transition the computer industry was going through. From a growth by increasing clock frequency (Hz) to increased performance by combining multiple cores.
Challenges#
With Dannard scaling smaller transistors allowed to ramp up the core clock rate and with a higher clock rate a CPU would simply process instructions faster, no adaption on the programs needed.
Combining multiple CPUs onto a microprocessor, on the other hand, does not have any effect on a program that is designed to run its instructions on a single core.
Leveraging multi-CPU structures requires a complete redesign of an algorithm or program!
In the past
In fact, already when we look back to Moore’s Law - stating that the number of transistors on a microprocessor doubles approximately every two years - we should wonder:
Why would we want to modify our UTM by adding more transistors if it is already a “universal” computer?
The reason is efficiency:
The definition of the Turing Machine ensures computability (can it be done?), but it does not include any notion of efficiency (how long will it take?).

Efficiency through complexity#
Microprocessors have continuously evolved not just to increase clock speed, but to increase their complexity, enabling more efficient instruction processing.
Moore’s Law laid the foundation for these efforts by providing the ‘transistor budget’ needed to add these complex features. Long before the ‘Power Wall’ was hit in 2005 (forcing the shift to multi-core), CPUs were already equipped with architectures allowing instructions to run partially in parallel (ILP), layers of on-chip memory (L1/L2/L3 Cache) for ultra-low latency, and dedicated circuits for specialized tasks.
Practically speaking, these adaptations created massive potential for efficiency. While some improvements (like Cache) sped up programs automatically, others (like specialized circuits) meant that software often needed to be redesigned to fully leverage this new potential.
With the switch to multi-core microprocessors, an efficient program could no longer rely on increasing clock speeds; instead, it needed to take advantage of the increased complexity and parallelism introduced. The predominant paradigm for such adaptations is Concurrency.
Sources:
https://en.wikipedia.org/wiki/Concurrency_(computer_science)
https://en.wikipedia.org/wiki/Multiprocessing
https://en.wikipedia.org/wiki/Multithreading_(computer_architecture)
https://en.wikipedia.org/wiki/Instruction-level_parallelism